
SEMINARSKI RAD IZ MULTIMEDIJE
OSTALI SEMINARSKI RADOVI
IZ MULTIMEDIJE |
|||||||||||||||
|
|||||||||||||||

KOMPRESIJA SLIKA BEZ GUBITKA INFORMACIJA
KOMPRESIJA SLIKE
U današnje vrijeme sve su veći zahtjevi za prenosom što veće količine podataka. To se pokušava realizovati hardware-skim rješenjima, koja ipak pomalo počinju dosezati svoje realne granice (ograničenja koja nameću same tehnološke mogućnosti), pa se pribjegava software-skim rješenjima, koja nastoje sliku sažeti na što manju veličinu, da bi se moglo prenijeti više slika u jedinici vremena, preko istog ograničenog prenosnog sistema. Kompresijom podataka (slika) mogu se postići izvrsni rezultati, npr. slika dimenzija 1024 pixela x 1024 pixela x 24 bita, bez kompresije zauzima oko 3 MB memorijskog prostora i potrebno je oko 7 minuta za njen prenos koristeći brzu 64 Kbit/s ISDN liniju, dok je za sliku kompresovanu u odnosu 10:1 potrebno 300 KB memorijskog prostora, a za njen prenos je potrebno oko 30 sekundi. Prenos velikih slikovnih fajlova predstavlja usko grlo distribuiranih sistema.Kod kompresije važni su prenosivost i performance. Današnja rješenja za kompresiju su relativno prenosiva (između različitih platformi) budući da uveliko zadovoljavaju međunarodne standarde.
Metode kompresije slike (“intraframe compression”) mogu se generalno podijeliti u dvije grupe:
Postoje dvije vrste algoritama za kompresiju slike :
- kompresija bez gubitka podataka (“lossless”)
- kompresija bez gubitka podataka (“lossless”)
Metode sa gubicima zasnivaju se na modelima ljudske percepcije (više kompresuju one atribute slike koji manje doprinose ukupnom izgledu slike) , one uzrokuju degradaciju slike u svakom koraku (svakim slijedećim korakom kompresije/dekompresije slika se degradira) , ali najčešće omogućuju daleko veće omjere kompresije nego metode bez gubitaka.
2. Metode kompresije bez gubitaka :
Ove metode osiguravaju identičnost dekompresovane i izvorne slike. Ovo je vrlo važno u nekim područjima, npr. u medicini gdje je osim visoke razlučljivosti potrebno i osigurati nepromjenjeno arhiviranje slika, što je i zakonski regulirano.
2.1. Run-length kodovanje
To je vrlo jednostavna metoda koja koristi činjenicu da su u mnogim fajlovima
česti nizovi istih vrijednosti (npr. jako korelirane slike). Ovaj algoritam
provjerava fajl, te ubacuje specijalne znakove (engl. ‘token’)
svaki put kad naiđe na niz od dva ili više jednakih znakova.
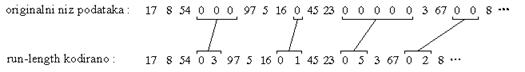
Slika 1.Run-length kod
Karakteristike : Lako se implementira, software-ski ili hardware-ski,
vrlo je brzo, lako se provjerava, ali ima ograničene mogućnosti kompresije.
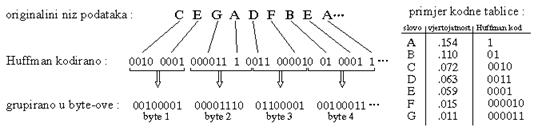
2.2. Huffman kodovanje
Ovaj algoritam je razvio D.A.Huffman i temelji se na činjenici da se
neki znakovi pojavljuju češće nego neki drugi. Na toj osnovi algoritam
izgrađuje težinsko binarno stablo (na osnovu frekvencije pojavljivanja
pojedinih znakova). Svakom elementu tog stabla pridružuje se nova kodna
riječ određena pozicijom znaka u stablu. Najčešće ponavljani znak postaje
korjen stabla i njemu se pridružuje najkraća kodna riječ, dok kodna riječ
najrjeđe ponavljanog znaka može biti i dvostruko duža od samog znaka.
Karakteristike : Odnos kompresije iznosi oko 1 : 2 za nekorelirane slike,
za tipične slike odnos kompresije iznosi oko 1 : 1.2 do 1 : 2.5.
Slika 2. Huffmanovo kodovanje
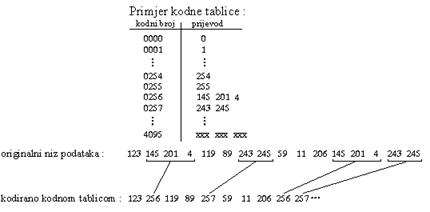
2.3. Entropijsko kodovanje
Najčešće se koristi pristup J.Ziv/Lempel (tzv. Lempel/Ziv ili LZ) koji
se zasniva na tome da koder i dekoder sadrže jednak riječnik metasimbola
od kojih svaki predstavlja cijelu sekvenciju ulaznih znakova. Ako se sekvencija
ponovi nakon što je pronađen simbol za nju, onda se ona zamjenuje tim
simbolom. Kodovani podaci ne trebaju sadržavati riječnik (nizovi znakova
= simbol) budući da je riječnik sadržan u koderu i dekoderu.
Karakteristike : Odnos kompresije iznosi do 1 : 8 za prosječne GIF slike,
relativno su problematični za implementaciju budući da sadrže tablice
koje rastu s izvođenjem algoritma.
Slika 3. Kodovanje kodnom tablicom
2.4. Kodovanje područja
To je poboljšana verzija run-length kodovanja koja iskorištava
dvodimenzionalnu karakteristiku slika. Algoritam pokušava pronaći pravougle
regije jednakih karakteristika koje se zatim koduju u opisnoj formi kao
elementi s dvije tačke i određenom strukturom. Cijela slika treba biti
opisana da bi se omogućilo dekodovanje bez gubitaka. Moguće performanse
temelje se na vrlo kompleksnom problemu pronalaženja najvećih područja
jednakih karakteristika.
Karakteristike: Vrlo je efikasan način kodovanja, ali zbog svoje nelinearnosti
onemogućuje hardware-sku implementaciju, te je relativno spor.
3. Metode kompresije sa gubicima :
Ove metode sastoje se od tri komponente :
- modelovanje slike (definicija transformacije koja se koristi)
- kvantizacija parametara (kvantizacija podataka dobijenih transformacijom)
- kodovanje
Prvi dio, modelovanje slike, usmjeren je na iskorištavanje statističkih karakteristika slike (npr. korelacija). Pokušava se da što manji broj koeficijenata u transformisanom domenu sadrži što veći dio informacija originalne slike. Ova faza najčešće ne rezultira nikakvim gubitkom informacija.
Cilj kvantizacije je da smanji količinu podataka potrebnu za predstavljanje informacija u novom domenu. Kod kvantizacije u većini slučajeva dolazi do gubitka informacija.
Kodovanje optimizuje reprezentaciju informacija, te se može unijeti detekcija grešaka.
Performanse algoritama za kodovanje s gubicima se najčešće izražavaju preko dva faktora:
- faktor kompresije
- distorzija proizvedena nakon rekonstrukcije
Prvi faktor je objektivan, dok drugi uveliko zavisi o samom izboru slike.
Danas se najčešće koristi transformaciono kodovanje kao što je npr. JPEG
budući da postoje već neki oblici standardizacije procesa.
4. PRIMJENE NAVEDENIH METODA
U nastavku navedeni su neki od primjera standardizovanih formata za kompresiju
slike u kojima se upotrebljavaju navedeni principi odnosno algoritmi.
JPEG (Joint Photographic
Experts Group), ime dolazi ravno iz
imena vijeća koje je sastavilo taj standard, a predstavlja način kompresije
koji najbolje djeluje na slike s puno boja ili slike sastavljene od nivoa
sive boje, koje prikazuju scene iz stvarnog svijeta. Dobar je za fotografije,
ali nije baš uspješan pri kompresiji jednostavnih crtanih slika ili linija,
ima problema s oštrim rubovima. Služi isključivo za kompresiju mirnih
slika.
Napravljen je tako da koristi nesavršenosti ljudskog oka, odnosno činjenicu
da se okom bolje primjećuju male razlike u svjetlini nego u boji. Ova
činjenica može stvarati izvjesne probleme, ako slike obrađene na ovaj
način ne analizira čovjek nego mašina.
Važna osobina JPEG metode je u mogućnosti traženja kompromisa između veličine
slike i njenog kvaliteta. Da bi bio dobar kvalitet, slike se ne mogu mnogo
kompresovati, ali ako nam nije jako važan kvalitet možemo postići visok
stepen kompresije. Postoji još jedna važna činjenica vezana za kvalitet
slike. Možemo birati između kvaliteta slike i brzine dekodovanja, koristiti
manje tačne aproksimacije, ali zato jako brze i obrnuto.
Posmatrajući slike iz stvarnog života JPEG gubi puno manje informacija
nego GIF, koji predstavlja također jednu metodu kompresije
slika. Jedini pravi nedostatak JPEG-a sastoji se od toga da svaki put
kada kompresujemo i ponovo dekompresujemo sliku gubimo sve više informacija.
Vrlo je važno ograničiti broj kompresija i dekompresija između početne
i završne verzije slike. Postoje neke operacije, rotacija za 90 , koje
se mogu izvesti, uz neka ograničenja u veličini slike, bez dekompresije
slike.
Posmatrajući GIF možemo zaključiti da postoje izvjesne primjene u kojima
daje bolje rezultate ne samo u kvalitetu nego i odnosu početne i kompresovane
slike. Takve primjene odnose se na slike koje sadrže samo nekoliko različitih
boja, kao što su nacrtane linije ili jednostavne crtane slike. Crno-bijele
slike ne bi se smjele pretvarati u JPEG format, potrebno je barem 16 sivih
nivoa da bi to imalo smisla.
JPEG može osigurati kompresiju 20:1 sa svim bojama bez vidljivih gubitaka
informacija. Nekompresovani podaci su veličine 24 bita po pixelu. Kompresija
od 30:1 do 50:1 moguća je uz manje i srednje gubitke dok je, za primjene
u kojima nije jako važan kvalitet, moguće postići kompresiju i 100:1.
Početna, ne kompresovana slika, za GIF format mora biti veličine 8
bita po pixelu. Može se osigurati kompresija 3:1, a uz neke dodatne
operacije i 5:1.
Osnovni JPEG format sprema se kao jedan prelaz preko slike od vrha do
dna. PROGRESIVNI JPEG podijeljen je u nekoliko prelaza
preko slike. Prvi prelaz daje sliku vrlo lošeg kvaliteta, ali zauzima
vrlo malo mjesta, sledeći postupno poboljšavaju kvalitet slike. Prednost
ovog načina je u tome, što se slika može vidjeti odmah nakon prenosa,
u početku lošijeg kvaliteta, ali s vremenom kako stižu novi podaci kvalitet
se popravlja. Ovaj način našao je svoju primjenu kroz popularnost World
Wide Web-a i njegovih pretraživača, koji rade sa sporim modemskim vezama.
LOSSLESS JPEG je potpuno drugačiji princip od osnovnog
JPEG-a, a najznačajnija prednost mu je garancija istovjetnosti svih bitova
deompresovane i originalne slike. Može izvršiti kompresiju podataka sa
svim bojama u odnosu 2:1, a upotrebljiv je isključivo na slike sa kontinualnim
prelazima boja.
Danas postoji i novi stanadard nazvan JPEG-LS koji omogućava
veći nivo kompresije, također bez gubitaka, ali je još uvijek puno lošiji,
po odnosu originalne i kompresovane slike, od osnovnog JPEG-a.
MPEG je standard za kompresiju pomičnih slika odnosno
videa ("motion picture compression"). Upotrebljava slične tehnike
kao JPEG. Koristi se činjenicom da su slike, koje slijede jedna za drugom,
a dio su nekog videa, u mnogočemu slične. Nedostaci se sastoje u tome
što je potrebno puno proračuna za generisanje kompresovane sekvence, vrlo
je teško editovati MPEG sekvencu na nivou pojedine sličice.
Vrlo često pojavljuje se M-JPEG, koji je vrlo popularan
za editovanje videa, ali je problem što nije definisan kao standard.
Postoji čitav niz korisničkih programa koji omogućavaju gledanje slika,
neki od njih su:
X WINDOWS odličan za gledanje JPEG, GIF i dr. , može
raditi konverzije između različitih formata, te neke jednostavnije transformacije
sa slikama.
WinJPEG prikazuje i vrši konverziju JPEG, GIF, TIFF,
BMP. Sadrži funkcije poput podešavanja boja i " slideshow"w-a
".
ACDsee je brz, dobar za JPEG, GIF, PNG , i dr. Nije moguće
vršiti editovanje slika niti konverzije formata.
LOSSLESS ALGORITMI
Lossless algoritmi |
Primjena |
Huffman |
MNP5 |
LZW (1984) |
GIF |
LZ77 |
ZIP |
LZ77, LZ78 I LZW ALGORITMI
LZ77, LZ78 i LZW algoritmi su algoritmi za kompresiju podataka bez gubitka informacija. LZW algoritam se koristi kod GIF kompresije slika.
Tri verzije algoritma:
- LZ77 i LZ78 algoritam – autori Abraham Lempel i Jacob Ziv, 1977. i 1978. godine respektivno
- LZW algoritam - autor Terry Welch 1984. godine je varijanta LZ78 algoritma
OSNOVNI PRINCIP: Dictionary based kompresija. To je kompresija koja koristi listu ili rječnik u kojem pamti sekvence nekompresovanog sadržaja. Tokom kompresije kada se sekvenca iz rječnika pojavi u nekompresovanom sadržaju ona se mijenja sa kodom iz rječnika koji referencira tu sekvencu. Sa povećanjem dužine sekvenci u rječniku i povećanjem frekvencije pojavljivanja istih u nekompresovanom sadržaju povećava se i kompresija.
Implementacija rječnika:
- LZ77 algoritam koristi sliding window u nekompresovanom sadržaju da generiše rječnik.
- LZ78 algoritam rječnik pravi dinamički koristeći nekompresovani sadržaj.
- LZW algoritam ima predefinisane vrijednosti stringova u svom rječniku prilikom inicijalizacije, tako da se rječnik sastoji od svih mogućih kombinacija stringova za dati opseg. Npr. ako kodiramo 8-bitne podatke, rječnik je inicijalizovan sa 256 1-bajtnih stringova sa vrijednostima od 0 do 255.
LZW KOMPRESIJA PSEUDOKOD
set w = NULL
loop
read a character k
if wk exists in the dictionary
w = wk
else
output the code for w
add wk to the dictionary
w = k
endloop
LZW DEKOMPRESIJA PSEUDOKOD
read a character k
output k
w = k
loop
read a character k
entry = dictionary entry for k
output entry
add w + first char of entry to the dictionary
w = entry
endloop
Postupak kompresije LZW algoritma:
- Čitaju se karakteri sa ulaza i dodaju na trenutni string, sve dok se ne dobije string koji ne postoji u rječniku.
- Tada se taj string dodaje u rječnik, on se sastoji od matching string-a i jednog dodatnog karaktera.
- Ponovo se počinje postupak sa novim stringom koji sadrži prvi nonmatching karakter.
- Svaki put kada se riječ upisuje u rječnik, generiše se izlaz.
PRIMJER
Input |
Output |
New Code |
A MAN A PLAN A CANAL PANAMA |
A |
|
MAN A PLAN A CANAL PANAMA |
<SPACE> |
256='A<SPACE>' |
MAN A PLAN A CANAL PANAMA |
M |
257='<SPACE>M' |
AN A PLAN A CANAL PANAMA |
A |
258='MA' |
N A PLAN A CANAL PANAMA |
N |
259='AN' |
A PLAN A CANAL PANAMA |
<SPACE> |
260='N<SPACE>' |
A PLAN A CANAL PANAMA |
256 |
261='A' |
PLAN A CANAL PANAMA |
P |
262='A<SPACE>P' |
LAN A CANAL PANAMA |
L |
263='PL' |
AN A CANAL PANAMA |
259 |
264='LA' |
A CANAL PANAMA |
261 |
265='AN<SPACE>' |
CANAL PANAMA |
<SPACE> |
266='<SPACE>A<SPACE>' |
CANAL PANAMA |
C |
267='<SPACE>C' |
ANAL PANAMA |
259 |
268='CA' |
AL PANAMA |
A |
269='ANA' |
L PANAMA |
L |
270='AL' |
PANAMA |
<SPACE> |
271='L<SPACE>' |
PANAMA |
P |
272='<SPACE>P' |
ANAMA |
269 |
273='PA' |
MA |
258 |
274='ANAM' |
STATISTIKA KOMPRESIJE
String ”A MAN A PLAN A CANAL PANAMA” ima 27 karaktera, 8
bita po karakteru, što je ukupno 216 bita za predstavljanje stringa.
LZW proces koristi 20 znakova plus rječnik, što znači da je potrebno 9
bita za predstavljanje svake LZW vrijednosti.
Ukupno je potrebno 180 bita za prestavljanje stringa, što je ušteda od
17%.
Ako ponovimo isti string dva puta, ušteda je 33%, a ako ponovimo isti
string tri puta ušteda je 41%.
LZW DEKOMPRESIJA
Dekompresija LZW algoritmom je jednostavna, svaku kompresovanu riječ treba jednostavno prevesti iz rječnika. Kodnu tabelu nije potrebno kodirati uz kompresovani sadržaj, jer se može odrediti dinamički, upravo na osnovu kodiranog sadržaja. Jedini problem koji se može javiti je da pokušamo dekompresovati riječ koja nije definisana u rječniku, kao u sledećem primjeru.
Input |
Output |
New Code |
ABYABABAX |
A |
256='AB' |
BYABABAX |
B |
257='BY' |
YABABAX |
Y |
258='YA' |
ABABAX |
256 |
259='ABA' |
ABAX |
259 |
260='ABAX' |
X |
X |
|
Primjetimo da je kod 259 definisan u isto vrijeme kada i izlaz. Dekoder koji procesira ovu sekvencu će pročitati 259 prije nego što je kod 259 definisan. Ova kolizija se rješava na sledeći način: Izlaz neposredno prije 259 je 259 i njegova vrijednost je “AB”. Zadnji karakter prethodnog kod (258) je “A”, pa je u rječniku za 259 string “AB”+”A”=“ABA“.
OGRANIČENJA U VELIČINI KODOVA
Ako imamo string do 256 bajtova dovoljno je 9 bita za predstavljanje
rječnika, za veće stringove moramo koristiti 10 bita, za još veće opet
moramo povećati broj bita u rječniku. Postavlja se pitanje kako odabrati
prikladnu veličinu bita u rječniku, očigledno ćemo imati lošu kompresiju
kod velikih input stream-ova. Rješenje je u tome da se veličina
rječnika određuje i povećava po potrebi dinamički.
Na početku kompresionog procesa svaka vrijednost se pamti koristeći najmanji
broj bita (skoro uvijek 9). Kada broj kodova postane preveliki da bi se
mogao predstaviti trenutnom kodnom veličinom, ona se inkrementira za 1.
Za 9 bita se povećava na 10 kada dostigne kodnu riječ broj 512, sa 10
na 11 bita kada dostigne kodnu riječ broj 1024. Maksimum veličine kodne
riječi kod GIF formata je 12 bita. Kada se dostigne riječ broj 212-1 prestaje
se sa dodavanjem kodnih riječi u rječnik. U tom slučaju GIF koder može
izdati clear code instrukciju, koja kaže dekoderu da resetuje
dekoder u inicijalno stanje. Vrijednost clear code ne mora biti
uvijek ista tj. instrukcija ne mora uvijek biti izdata kad se dostigne
broj 212-1.
Kada se završi kodovanje koder šalje instrukciju end code da
označi kraj kompresovanog stream-a.
STRUKTURA RJEČNIKA
Do sada smo prikazivali rječnik kao niz stringova, međutim u praksi nije tako. Rječnik je prestavljen u obliku stabla, kao na primjeru riječi ABABCABD.
256=AB |
Kod može biti preveden u string obilaskom stabla od lišća prema korijenu, što u svakom prolazu daje string u obrnutom redoslijedu. Dok obilazimo stablo svaki put kada naiđemo na list odgovarajući karakter se stavlja na stek. Kada dostignemo korijen stabla vadimo sve elemente sa steka i tako dobijamo korektan redoslijed karaktera u stringu. Maksimalna veličina steka je 212.
VREMENSKA KOMPLEKSNOST
Kompresija: O(n) gdje je n dužina teksta koji se kompresuje
Dekompresija: O(n) gdje je n dužina dekompresovanog teksta
PITANJE INTELEKTUALNE SVOJINE
- LZW je zaštićen patentom, firma Unisys.
- Prvi GIFje napravljen u firmi CompuServe ne znajući da je algoritam patentiran.
- Nakon što je GIF postao jako popularan firma Unisys je zahtijevala da svi koji koriste GIF format plate nadoknadu.
- Ovaj sudski spor ubrzava rađanje PNG formata, koji ubrzo postaje preporučen
od strane W3 konzorcijuma.
Windows Bitmap
Windows bitmap format je razvio Microsoft kao "device-independent bitmap" (.dib) fajl format, što znači da bitmap određuje boju piksela nezavisno od načina na koji displej predstavlja tu boju. Na početku je bilo više nekompatibilnih verzija, ali kako je Microsoft imao potpunu kontrolu nad formatom te verzije nikada nisu zaživjele.
Format je utvrđen sa Windows 3.0 verzijom. Od tada su napravljene neka poboljšanja, ali su potpuno kompatibilna sa predhodnim verzijama formata. Podrazumijevana ekstenzija za Windows DIB je .bmp. Koriste ga Microsoft Windows i OS/2 grafički podsistemi, i uopšteno se koristi kao jednostavan grafički format na tim platformama.
Slike se memorišu sa 2 (1-bit), 16 (4-bita), 256 (8-bita), 65,536 (16-bita) ili 16,7 miliona (24-bita) boja. 8-bitna slika može da bude siva slika (greyscale), ili indeksirana slika u boji. Alfa se smješta u odvojen fajl, slično sivoj slici. 32-bitni format sa integrisanim alfa je predstavljen sa Windows XP verzijom.
BMP fajlovi su obično bez kompresije, tako da zauzimaju dosta memorijskog prostora. Zbog toga su ovi fajlovi nepodesni za prenos preko Internet-a, ili drugih sporih ili medija malog kapaciteta. Prednost ovog formata je sama jednostavnost, kao i to što je visoko standardizovan i jako proširen.
Tipičan format fajla
Tipičan bit-mapirani fajl se sastoji iz 4 dijela:
- Zaglavlje fajla - informacije o fajlu,
- Informaciono zaglavlje - detaljne informacije o samoj slici,
- Paleta boja - definiše boje koje se koriste,
- Pikseli.
Zaglavlje fajla
To je blok bajtova koji se koristi za identifikaciju. Aplikacije ga koriste da bi utvrdile da li se radi o .bmp fajlu i da li je oštećen. Veličina ovog zaglavlja je obično 14B, a podijeljeni na sledeći način:
- 2B - identifikacija fajla, "BM",
- 4B - veličina fajla u bajtima,
- 4B - ne koriste se, moraju biti 0,
- 4B - offset, govori gdje se nalaze sami pikseli.
Informaciono zaglavlje
Sadrži informacije koje se koriste prilikom prikazivanja slike na ekranu. Postoje dva formata ovog zaglavlja, jedan je razvijen za OS/2 (veličina zaglavlja je tačno 12B), a drugi je razvijen za Windows (veličina zaglavlja je najmanje 40B). Prva 4B u oba slučaja definišu veličinu zaglavlja, tako da je lako utvrditi o kojem formatu se radi. Tipično zaglavlje za Windows je podijeljeno na sledeći način:
- 4B - veličina zaglavlja [B],
- 4B - širina slike [pixel],
- 4B - visina slike [pixel],
- 2B - broj ravni koji se koristi, ne koristi se često, fiksna vrijednost je 1,
- 2B - broj bita po pikselu, tipične vrijednosti su 1, 4, 8, 24 i 32,
- 4B - način kompresije koji je korišten, moguće vrijednosti su 0-5, tipično 0 (bez kompresije),
- 4B - veličina slike [B],
- 4B - horizontalna rezolucije slike [pixel/m],
- 4B - vertikalna rezolucije slike [pixel/m],
- 4B - broj boja koje se koristi,
- 4B - broj značajnih boja.
Paleta boja
Paleta boja ne mora uvijek da postoji. Koriste je BMP slike koje piksel predstavljaju sa najviše 8 bita. Slike sa više od 1B/pixel su intenzitetske slike.
Tipičan BMP fajl koristi RGB model. Kada paleta boja postoji sadrži više ulaza (broj ulaza zavisi od broja boja koje se koriste), gdje svaki ulaz ima 4B. Prva tri bajta predstavljaju plavu, zelenu i crvenu boju respektivno, dok se četvrti bajt ne koristi (mor biti 0).
Pikseli
Ovaj blok sadrži podatke koji zapravo predstavljaju sliku. Ako broj
B kojima je predstavljena horizontalna linija slike nije djeljiv sa 4,
na kraj se dodaju nule. Recimo da imamo sliku 1071x363, koja za svaki
piksel koristi 24 bita. Znači imamo 1089B po redu. Kako 1089 nije djeljivo
sa 4 na kraj svakog reda se dodaju 3B, čija je vrijednost 0 tako da dobijamo
1092B po redu.
GIF
GIF (Graphics Intechange Format) je uveo CampuServe 1987. godine. Definiše protokol za prenos "raster" slike na način koji je nezavisan od platforme na kojoj je slika kreirana i na kojoj će se prikazivati. Koristi kompresiju sa gubitkom, i kompresiju bez gubitka (LZW algoritam). LZW algoritmom veličina fajla može znatnao da se smanji, bez gubitka u kvalitetu slike.
Postoje dvije verzije ovog formata:
- 87a verzije koja je uvedena 1987. godine i koja definiše osnovnu strukturu formata,
- 89a verzija proširuje format, omogućava komentare i smjernice.
Prilikom pisanja GIF fajla koji ne zahtijeva 89a verziju preporučuje se navođenje 87a verzije (sama verzija definiše minimalne mogućnosti koje aplikacija mora imati da bi otvorila fajl).
Pikseli su organizovani kao sekvenca blokova i podblokova u kojima su smješteni određeni podaci koji se koriste pri reprodukciji slike. GIF format podržava i animacije gdje se za svaki frejm koristi odvojena paleta.
Osnovni format fajla
Kako fajl može da sadrži bilo koji broj slika, i bilo koji broj proširenja, struktura samog fajla je jako kompleksna. Osnovna kompozicija fajla bi se mogla opisati na sledeći način:
- Zaglavlje fajla - definiše verziju koja se koristi ( "GIF89a" ili "GIF87a" ),
- Deskriptor logičkog ekrana - sadrži parametre koji definišu logički prostor na kojem će slika biti prikazana,
- Globalna paleta (opcionalna) - 256 ulaza po 3B (RGB), koriste je slike koje nemaju lokalnu paletu,
- Definicija bloka,
- "File trailer" - ";" .
Deskriptor logičkog ekrana
Veličina ovog bloka je 7B. Sadrži sledeće parametre:
- 2B - širina logičkog ekrana, [B],
- 2B - visina logičkog ekrana, [B],
- 1B - pakovani podaci, 0-2 biti sadrže veličinu globalne palete ako postoji umanjenu za jedan; 3 bit određuje da li je paleta sortirana po važnosti (0 - ne, 1 - da) ; 4-6 biti sadrže rezoluciju (broj bita po boji koji se koristio u originalnoj slici - 1); 7 definiše da li postoji globalna paleta (0 - ne, 1 - da),
- 1B - indeks za boju pozadine, važeći je samo ako postoji globalna paleta i tada određuje ulaz u tabeli koji određuje boju pozadine ( boju koja se prikazuje ako učitani piksel nije u paleti),
- 1B - "pixel aspect ratio".
Definicije blokova
Ovaj dio može da sadrži neograničen broj slika i 89a proširenja u bilo kojem rasporedu.
Blokovi se mogu podijeliti u tri osnovne grupe: kontrolni blokovi, blokovi za tumačenje slike, i blokovi za specijalne namjene. Tip bloka se može odrediti na osnovu prvog bajta u bloku: 0x00-0x7F (0-127) kontrolni blokovi, 0x80-0xF9 (128-249) blokovi za tumačenje slike, 0xFA-0xFF (250 - 255 ) blokovi za specijalne namjene.
Blokovi slike sadrže sledeće informacije:
- Deskriptor slike,
- Lokalna paleta - ista struktura kao kod globalne, prvo se provjerava da li postoji lokalna paleta, ako ne postoji koristi se globalna,
- Minimalna veličina LZW koda,
- Podaci o pikselima slike,
- Blok terminator - 1B koji sadrži 0x00.
Minimalna veličina LZW koda zapravo odredjuje broj ulaza u inicijalnoj tabeli koje se koristi pri kompresiji i dekompresiji. GIF podržava kodove dužine do 12 bita. Podaci o pikselima su podijeljeni u podblokove, svaki podblok počinje bajtom koji određuje njegovu veličinu (tako da jedan podblok može da sadrži najviše 255B).
Deskriptor slike sadrži:
- 1B - separator slike - definiše početak deskriptora slike, 0x2C,
- 2B - offset lijeve ivice slike [pixel],
- 2B - offset gornje ivice slike [pixel],
- 2B - širina slike [pixel],
- 2B - visina slike [pixel],
- 1B - pakovana polja - 0-2 biti određuju veličinu lokalne palete - 1, ako ona postoji; 3-4 biti se ne koriste (moraju biti 0), 5 određuje da li je lokalna paleta sortirana po važnosti, 6bit "interlacing" fleg, 7 bit određuje da li postoji lokalna paleta.
Svaka slika u GIF fajlu se sastoji iz deskriptora slike, lokalne palete (opcionalno) i podataka o pikselima. Isto tako, svaka slika mora da odgovara granicama koje određuje deskriptor logičkog ekrana.
LZW za GIF
LZW algoritam koji koristi GIF odgovara standardnom LZW algoritmu sa sledećim razlikama:
- definiše se dodatni parametar "clear code" koji resetuje sve parametre kompresije na početno stanje. Vrijednost ovog koda je 2n gdje je n minimalna vrijenost LZW koda koja se nalazi prije samih piksela.
- definiše se kod za kraj podataka čija je vrijednost jednaka "clear code" + 1. Mora biti na kraju samih piksela slike. Kada se ovaj kod pojavi prekida se LZW procesiranje.
- prvi kompresioni kod koji može da se koristi je "clear code" + 2.
- dužina koda nije stalna. Kreće se sa dužinom koda koja je jednaka minimalna dužina LZW kod + 1 do 12 bita po kodu. Najveća vrijednost za kod je 4095.
preuzmi
seminarski rad u wordu » » »
